
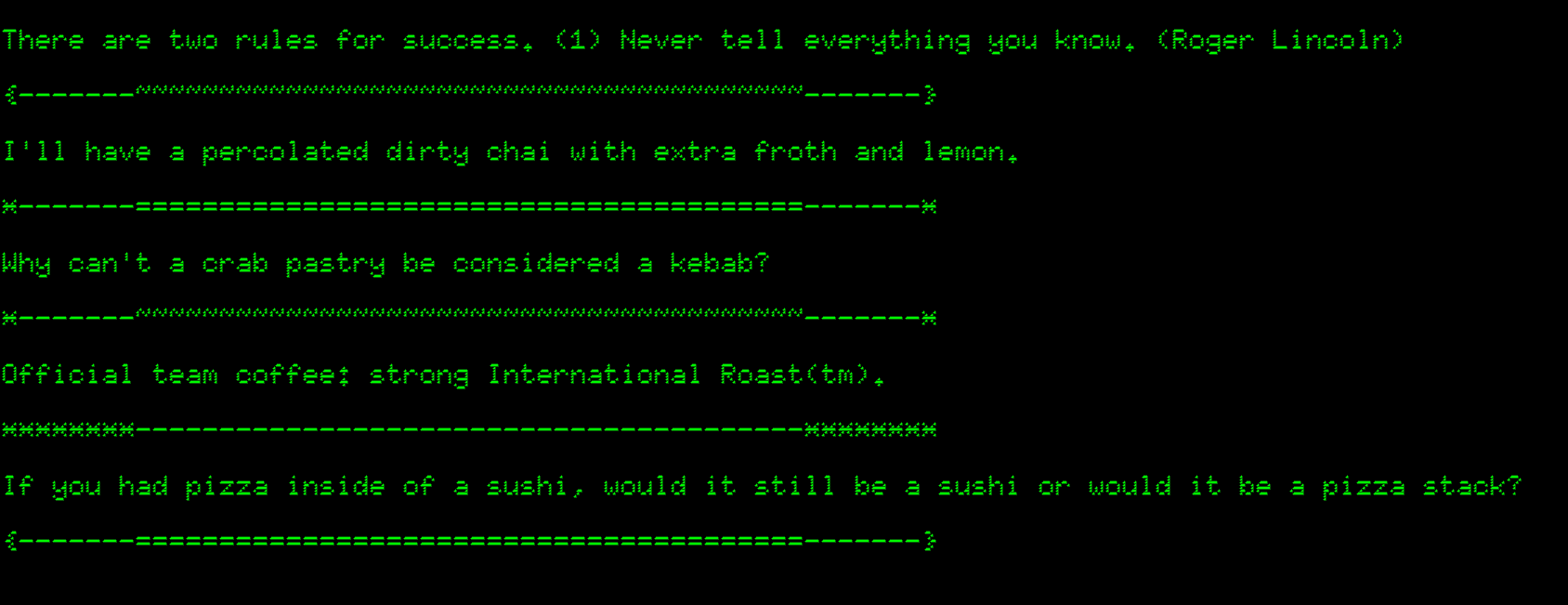
My colleagues and I tend to have stand-up meetings around the lab where our computers are. I could not abide by the standard screensavers, so wanted to customize my own using procedurally generated text. Now during meetings my screensaver distracts my colleagues with coffee orders or ontological conundrums. This post shows how you’d accomplish a similar productivity tweak.
If you are new to Tracery in Python, check out my other tutorial which goes through the basics. This post shows how to write a simple program using tracery, and a few key techniques to get interesting text.
The code is all available on Github: https://github.com/BrettWitty/procgen-screensaver
If you have any feedback, hit me up at @BrettWitty on Twitter.
The Screensaver
The screensaver part of this is relatively easy because I cheat. I use xscreensaver which allows you to choose any program to provide text to a screensaver. In writing a program that outputs procedurally-generated text, you now just hook that into xscreensaver and choose a screensaver that shows it off. I use phosphor for that retro style.
In general the text I output is a line of text, followed by a generated divider. You can omit the divider, but I feel like it separates the text nicely and small tweet-like passages are more encouraging to read than walls of text.
Procedural Generator Outputs
We will write a few generators. The more generators of greater complexity, the more interesting the outputs. The demo code has:
- Coffee order generator (
"So the coffee order is: a black coffee with two sugars and marshmallows; and a percolated chai with a tiny bit of chocolate shavings.") - Other coffee related outputs (
"A code monkey is a device for turning a warm dirty chai with a tiny bit of almond milk into programs.") - A food ontology puzzler (
"How would you define a burger? Would that also include meat-free seafood sandwiches?") - Random curated quotes
The dividing lines themselves are procedurally generated for added interest.
Code
File: procgen.py
Text framework
Tracery is a framework for text generation. You provide a grammar, which takes certain text tokens and replaces them with other text tokens, and some initial text. Tracery will then randomly generate text from that initial input. Generating text is called “flattening” because it squishes any special tokens into text until there are no more special tokens.
Our overall structure is to produce funny lines of text and then a dividing line drawing. Therefore the core of the screensaver is just:
1 2 3 | |
#main# is just a way of providing all our Tracery generators at a
top level, and let it choose the generator and then the results of the
generator as it flattens it.
For debugging or just preference, we might want to output a single generator, so the core of the program becomes:
1 2 3 4 5 6 7 8 | |
Now we can debug via python3 procgen.py coffee and the coffee
generator will spit out an answer. You can do this for any of the
generators you have. For example, python3 procgen.py numcoffees will
generate something from the coffee sub-generator that chooses the
number of coffees.
Reading in generators
The only remaining things to do are read in the generators from disk and write the grammars. The former is easy, and the latter is fun.
In procgen.py we put the names of the generators into a JSON file and read them all in sequentially. This is an easy way to add or delete generators, but you might like just one giant JSON file. Either way works.
Each generator is a JSON dictionary and we append them to a main
rules dictionary and convert that to a Tracery grammar.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
We now put this into main(), include all our libraries and we have the code done!
Writing our generators
The rest of this post will look at the generators of interest and show how they work, and any Tracery tricks they employ.
Quotes
File: quotes.json and warning.json
This is the simplest of all. Just create a JSON dictionary with quotes and a list of quotes.
{
"quotes" : [
"Programming is meat teaching sand to think with lightning.",
"Ten factorial seconds is exactly 6 weeks.",
"Planning is a form of path-finding.",
"...etc..."
]
}
Why this way and not just a JSON list of quotes? quotes is the
Tracery rule to generate quotes. We need to select it with #quotes#
and then when Tracery flattens that, it randomly selects a quote.
warning is a special set of quotes designed to guilt co-workers
reading the screensaver. Separating it out gives the quotes and
warning equal chance of being chosen.
Line drawing
File: linedrawing.json
This simple generator has three parts: left side, right side and the middle. We choose the middle arbitrarily, but the left and right sides need to be matched up. For example:
}-------========================================-------{
The middle is 40 =, and the left and right sides have - with an outer curly parenthesis.
To generate this we first have to choose our left and right side ornaments, then assemble:
{
"linedrawing" : [ "\n#ornament##leftline##midline##rightline#" ],
"ornament" : [
"[leftline:--------][rightline:--------]",
"[leftline:========][rightline:========]",
"[leftline:~~~~~~~~][rightline:~~~~~~~~]",
"[leftline:********][rightline:********]",
"[leftline:@-------][rightline:-------@]",
"[leftline:#-------][rightline:-------#]",
"[leftline:%-------][rightline:-------%]",
"[leftline:*-------][rightline:-------*]",
"[leftline:+-------][rightline:-------+]",
"[leftline:{-------][rightline:-------}]",
"[leftline:}-------][rightline:-------{]",
"...etc..."
],
"midline" : [
"----------------------------------------",
"========================================",
"~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~",
"________________________________________"
]
}
#ornament# uses assignment to leftside and rightside, and then we can use those in linedrawing.
If you need to establish context or ensure that things go together, this assignment trick is handy.
Food ontology
File: ontology.json
This one is slightly more complicated. It picks from some stock mad-lib style sentences and adds in the detail with sub-generators.
One trick employed is the “empty modifier” trick. If I have
#foodtype##foodstuff# with no separation, then one of the options for foodtype can be the empty string. This allows both meat pie
and just pie. The downside is that you have to make sure all your
foodtype have a trailing space.
Another trick is to mess with the probabilities. By adding the same option in multiple times, this means it has a better probability of being chosen.
The ontology example also uses context saving (afood and bfood) so
you can reuse specific results from a generator:
"[afood:#foodstuff#][bfood:#foodstuff#]What is more like a #foodmodifier##foodstuff#:
#afood.a# inside of #bfood.a# or #bfood.a# inside of #afood.a#?"
can yield
What is more like a calzone: a kebab inside of a burger or a burger inside of a kebab?
Coffee
File: coffee.json
The coffee generator branches out into a variety of sub-generators. It combines some of the tricks above, and adds some of its own.
For example "So the coffee order is: #coffeeorder1#." uses
coffeeorder1, which calls coffeeorder2. Both generate a random
coffee. The difference between the two is that coffeeorder2 will
call itself two-thirds of the time, but one-third of the time will add
one last coffee and finish. In other words, coffeeorder1 starts the
list and coffeeorder2 continues or ends the list.
These recursive structures allow for some interesting results. Occasionally it will create a coffee order a half-page long, with a bizarre variety of hot beverages.
I also use the English modifiers. #coffeeadj.a# coffee will produce
a cold coffee or an iced coffee correctly.
One last tip answers the question: “How large should each subgenerator be?” The precise answer depends on the grammar involved, but the more tree-like or recursive the grammar, the more potential unique results you have.
But even with the simplest of generators, say coffeetype which
chooses a type of coffee, I trawled Wikipedia and the dim recesses of
my mind to find 17 different types (with latte tripled and coffee
doubled to boost their probability). If I have a grammar:
#coffeetype.a# and #coffeetype.a# then thanks to the birthday
problem, I will
expect silly repetitive answers (`an espresso and an espresso’) about
1 in every \(\sqrt{17}\) generations, so about 1 in 4.
Thus in the leaves of your tree of generators, you need to add a lot
of examples to avoid repetition. The basic way to do this is add
modifiers like adjectives (extra hot coffee) or additional details (coffee with oat milk). 17 coffee types with 13 coffee adjectives yields \(17 \times 13 = 221\) possibilities, which will only have a
repeat once every 14.8 generations, on average.
Wrap-up
This was a quick exploration of how to make basic procedural generation to annoy and enlighten your co-workers. With a good base, you can tend to the JSON files over time, building up complexity or trimming away jokes that no longer work.
As always, if you liked this or have any feedback, let me know on Twitter: @BrettWitty.